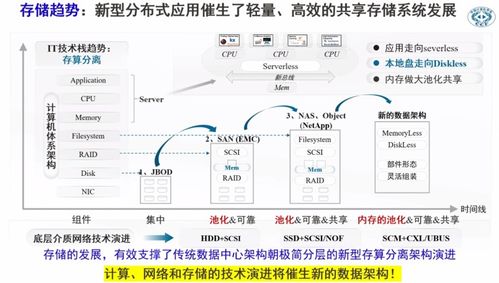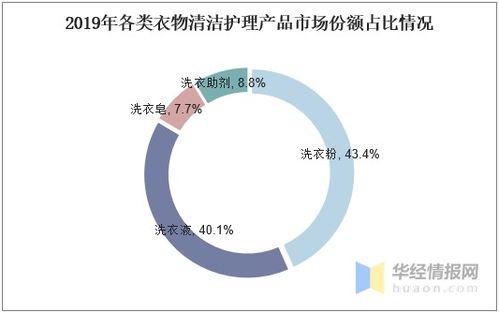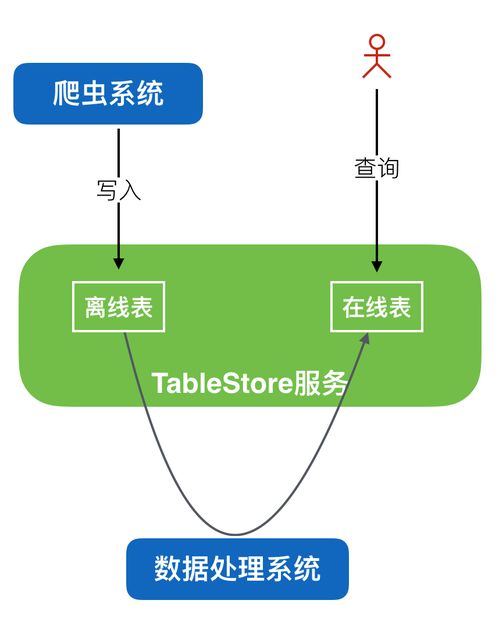
在當(dāng)今數(shù)據(jù)驅(qū)動的時代,爬蟲已成為獲取海量信息的重要手段。隨著數(shù)據(jù)量的激增,傳統(tǒng)的關(guān)系型數(shù)據(jù)庫在存儲和查詢爬蟲數(shù)據(jù)時常常面臨性能瓶頸和擴展性挑戰(zhàn)。阿里云的Tablestore(表格存儲)作為一種高性能、高擴展、全托管的NoSQL數(shù)據(jù)庫服務(wù),正成為處理大規(guī)模爬蟲數(shù)據(jù)的理想選擇,堪稱數(shù)據(jù)處理與存儲領(lǐng)域的利器。
一、Tablestore的核心優(yōu)勢:為爬蟲數(shù)據(jù)量身打造
1. 海量存儲與彈性擴展
爬蟲數(shù)據(jù)通常具有數(shù)據(jù)量巨大、增長迅速的特點。Tablestore支持PB級數(shù)據(jù)存儲和萬億行級別數(shù)據(jù)規(guī)模,并能實現(xiàn)自動的彈性伸縮。用戶無需預(yù)先規(guī)劃容量,也無需手動分庫分表,系統(tǒng)可根據(jù)數(shù)據(jù)量和訪問壓力自動調(diào)整資源,輕松應(yīng)對數(shù)據(jù)量的爆發(fā)式增長。
2. 高性能讀寫與低延遲
對于需要實時入庫和查詢的爬蟲應(yīng)用,讀寫性能至關(guān)重要。Tablestore提供了極高的讀寫吞吐能力(單表可達(dá)千萬級QPS)和毫秒級的低延遲訪問。其數(shù)據(jù)模型(寬表模型)特別適合存儲結(jié)構(gòu)相對固定但可能包含大量列的爬蟲結(jié)果(如網(wǎng)頁標(biāo)題、內(nèi)容、URL、抓取時間、各類元數(shù)據(jù)等),支持高效的隨機讀寫和范圍查詢。
3. 靈活的數(shù)據(jù)模型與多維度查詢
Tablestore提供了兩種數(shù)據(jù)模型:寬表(Wide Column)模型和時序(Timeline)模型。
- 寬表模型:非常適合存儲結(jié)構(gòu)化的爬蟲數(shù)據(jù)。每行數(shù)據(jù)由主鍵(必須)和屬性列(可選,可動態(tài)擴展)組成。例如,可以以
URL的MD5作為主鍵,存儲該頁面的所有抓取信息。
* 時序模型:特別適合存儲按時間序列產(chǎn)生的爬蟲狀態(tài)、監(jiān)控日志或增量內(nèi)容更新。
Tablestore支持多元索引功能。即使查詢條件不包含主鍵列,也能通過創(chuàng)建索引實現(xiàn)多條件組合查詢、全文檢索、模糊匹配、地理空間查詢等復(fù)雜搜索,極大提升了數(shù)據(jù)查詢的靈活性。例如,可以快速查詢“某個域名下、最近一周抓取的、包含特定關(guān)鍵詞的所有頁面”。
4. 強大的數(shù)據(jù)生命周期管理
爬蟲數(shù)據(jù)往往具有時效性,歷史數(shù)據(jù)可能需要歸檔或清理以節(jié)省成本。Tablestore支持為表或數(shù)據(jù)行設(shè)置生存時間(TTL)。超過指定時間的數(shù)據(jù)會自動過期刪除,這為管理海量歷史爬蟲數(shù)據(jù)提供了自動化、低成本解決方案。
二、典型應(yīng)用場景與實踐
1. 大規(guī)模分布式爬蟲數(shù)據(jù)倉庫
作為爬蟲系統(tǒng)的核心存儲,統(tǒng)一存儲來自成千上萬個爬蟲節(jié)點的數(shù)據(jù)。利用其高吞吐能力,可以承受高并發(fā)寫入;利用多元索引,可以方便地供下游分析系統(tǒng)或搜索服務(wù)進行多維度數(shù)據(jù)查詢和消費。
2. 去重與增量抓取
利用Tablestore主鍵的唯一性,可以高效實現(xiàn)URL去重。爬蟲程序在抓取前,先查詢主鍵(如URL指紋)是否存在,從而避免重復(fù)抓取,節(jié)省資源。
3. 爬蟲任務(wù)管理與狀態(tài)跟蹤
可以創(chuàng)建專門的表來管理爬蟲任務(wù)隊列、記錄任務(wù)狀態(tài)(待抓取、抓取中、成功、失敗)、重試次數(shù)等信息。利用其高并發(fā)讀寫能力,多個爬蟲節(jié)點可以高效、協(xié)同地領(lǐng)取和處理任務(wù),避免沖突。
4. 內(nèi)容分析與元數(shù)據(jù)存儲
存儲清洗和解析后的結(jié)構(gòu)化數(shù)據(jù),如商品信息、新聞文章、公司信息等。結(jié)合多元索引的全文檢索和統(tǒng)計聚合能力,可以快速構(gòu)建內(nèi)部的數(shù)據(jù)查詢平臺或分析應(yīng)用。
三、使用流程簡述
- 規(guī)劃數(shù)據(jù)模型:設(shè)計主鍵(通常選擇能唯一標(biāo)識數(shù)據(jù)的字段,如URL哈希),確定基本屬性和需要建立多元索引的字段。
- 創(chuàng)建實例和表:在阿里云控制臺或通過SDK創(chuàng)建Tablestore實例和數(shù)據(jù)表,根據(jù)需要配置讀寫容量、TTL等。
- 數(shù)據(jù)寫入:爬蟲程序通過官方提供的多語言SDK(Java, Python, Go, PHP等)將抓取到的數(shù)據(jù)以行為單位寫入Tablestore。
- 建立索引:為需要復(fù)雜查詢的字段創(chuàng)建多元索引。
- 數(shù)據(jù)查詢與分析:通過主鍵查詢、范圍查詢或多元索引查詢來獲取數(shù)據(jù),供后續(xù)處理、展示或分析使用。
四、
Tablestore憑借其全托管、無限擴展、高性能、低成本的特性,完美契合了大數(shù)據(jù)爬蟲場景下對數(shù)據(jù)存儲與查詢的苛刻要求。它將開發(fā)者從繁瑣的數(shù)據(jù)庫運維、分片設(shè)計和性能調(diào)優(yōu)中解放出來,使其能夠更專注于爬蟲邏輯與數(shù)據(jù)價值挖掘本身。無論是構(gòu)建大型垂直爬蟲系統(tǒng)、通用搜索引擎的數(shù)據(jù)后端,還是進行海量網(wǎng)絡(luò)數(shù)據(jù)的歸檔與分析,Tablestore都是一件值得信賴的“利器”,能夠為數(shù)據(jù)處理與存儲服務(wù)提供堅實、高效的底層支撐。